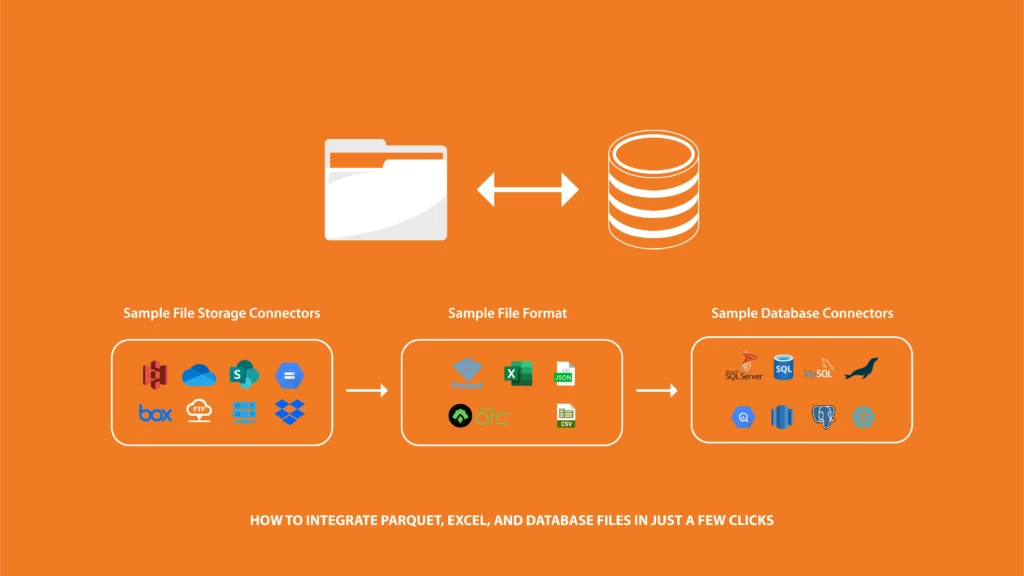
Data integration has always been a challenging task, especially for data engineers, analysts, and IT managers in medium-sized businesses. Managing multiple file formats, performing manual transformations, and keeping data synchronized across different systems is often complex. DataFinz is here to simplify this process by offering an intuitive platform that allows you to integrate Parquet, Excel, and database files in just a few clicks. Let’s explore how.
DataFinz’s ability to connect to diverse file storage solutions such as Amazon S3, Azure Data Lake, OneDrive, and Google Cloud Storage makes it adaptable to different business environments. This versatility is crucial in today’s data landscape, where organizations often utilize multiple platforms for data storage. Additionally, the solution supports both legacy and modern databases, ensuring that users can integrate with existing systems while embracing new technologies.
Understanding your organization’s unique data storage needs is essential for maximizing efficiency. DataFinz eliminates barriers between different systems, enhancing data accessibility and reducing the time spent on data management.
Why This Matters for You
Reduced Complexity: No need to switch platforms or tools. Connect and integrate from various sources without extra effort.
Scalable: As your data grows, DataFinz adapts, making it an ideal long-term solution.
The ODS pipeline (Operational Data Store) from DataFinz allows users to easily extract, transform, and load (ETL) data from multiple sources. This automated solution not only simplifies the integration process but also enables real-time data synchronization, which is vital for making informed decisions. With a user-friendly interface, data professionals can set up integrations without extensive technical knowledge, making it accessible for various team members.

One of the standout features of the ODS pipeline is its flexibility. Users can choose the best extraction methods and data quality checks tailored to their workflows, ensuring a seamless experience.
What Makes It Unique
How It Helps
When using DataFinz’s ODS pipeline, there are three primary components that drive the system and make it efficient. Understanding these components is crucial for leveraging the full potential of the platform. Each component plays a vital role in ensuring seamless integration and effective data management, making the process smooth and intuitive.
1. Connection: Securely connect to both file storages and databases. This component allows for a smooth and reliable data transfer between the different sources.
2. ODS Pipeline: Handles all the heavy lifting by integrating extraction, transformation, and loading processes.
3. Scheduler: Automates the timing of data loads, ensuring that data is always up-to-date without manual intervention.
Why It’s Important
Automation: No need for constant manual checks—scheduling keeps your data fresh.
Reliability: The connection component ensures that your data sources remain stable and secure during the integration process.
Here’s a simple walkthrough of how you can integrate an Excel file from Amazon S3 into SQL Server using the DataFinz ODS pipeline. This guide is designed to help data engineers and analysts perform the integration smoothly, providing a clear process to follow. Each step is straightforward, ensuring that even those with limited technical experience can navigate the integration process effectively.
Start by opening the DataFinz platform. The first task is to create a connection to your Amazon S3 file storage. This step ensures that DataFinz can access the files you need for integration.
Next, set up a target connection to SQL Server. This is where your data will be loaded after processing. By establishing these connections, you enable a seamless flow of data from your source to your destination.
Make sure to double-check your authentication details, such as access keys for Amazon S3 and database credentials for SQL Server. Proper configuration at this stage will save you time and hassle later on.
Lastly, test the connections to ensure they are working correctly. This simple check will confirm that DataFinz can communicate with both the file storage and the database without any issues.

In this step, you will configure the pipeline to handle your data. Begin by selecting the file type you want to work with—Excel in this case. This selection is crucial as it defines how DataFinz will process the data.
Next, choose the specific file(s) you want to extract from Amazon S3. If you have a large number of files, applying filters can help you narrow down the records you need, making your workflow more efficient.
Define data quality rules to maintain the integrity of your data. Set rules for handling null values and identifying duplicate records. These checks are essential for ensuring that the data you load into SQL Server is clean and accurate.
Once the configuration is complete, select the load type. Choosing the sync option allows DataFinz to insert new records while updating existing ones automatically. This way, your SQL Server remains up-to-date with the latest information.
The system can also create target tables in SQL Server automatically if they do not already exist. This feature simplifies the loading process, allowing you to focus on your data rather than on database management.
For customization, consider downloading a transformation template. You can make specific edits to this template based on your unique data requirements and re-upload it to implement those changes in your workflow.

To make your data integration process more efficient, you can automate it using the scheduler feature. This allows you to set the pipeline to run at specific intervals—daily, weekly, or even in real-time.
Automating the pipeline means you do not have to manually trigger data updates, saving you time and effort. You can simply set it and forget it, allowing DataFinz to handle the rest.
Choose a frequency that aligns with your business needs. For example, if your data changes frequently, a daily schedule may be best. For less dynamic data, a weekly schedule might suffice.
Monitoring your scheduled tasks is also essential. DataFinz provides notifications or logs to keep you informed about the status of your automated pipelines, ensuring you remain aware of any issues that may arise.
Finally, the automated scheduler helps maintain current and accurate data in your systems. This capability is crucial for making informed business decisions based on the latest insights without manual intervention.

There are several reasons why data professionals choose DataFinz for their integration needs. Understanding these benefits can help organizations realize the potential impact of streamlined data integration on their operations. From enhanced efficiency to improved data quality, DataFinz empowers teams to focus on strategic initiatives rather than manual data management.
In a world where timely and accurate data is crucial for business success, integrating data from different file types such as Parquet, Excel, and databases doesn’t need to be a complex task anymore. DataFinz provides an easy-to-use platform with versatile file connectivity, flexible pipelines, and automated scheduling, all designed to make data integration more accessible for medium-sized IT businesses. Whether you’re a data engineer, IT manager, or BI professional, DataFinz allows you to achieve faster insights and streamline your operations with minimal manual effort.